PART 2: The Network Revolution - How Hyperscalers Built the Backbone of Cloud Computing

From Latency Crisis to $500 Billion Industry: The Infrastructure Bet That Changed the Internet
If you haven't read Part 1 yet, start there. We covered how Amazon's discovery that every 100 milliseconds of latency costs them 1% in sales forced them to completely rethink their architecture — breaking their monolith into microservices, deploying aggressive caching, and tuning every protocol they could find. They solved the software problem.
But then they hit a wall.
No amount of software optimization could change one fundamental reality: data centers in Virginia were 80ms away from California customers and 200ms from Asian customers. The engineers had run out of code to write. The only thing standing between them and their users was physics.
The speed of light isn't negotiable.
So, between 2005 and 2015, Google, Amazon, Microsoft, and Facebook made a collective decision that seemed almost irrational at the time: to spend $10–30 billion each on building private global network infrastructure from scratch. This is what we call death of transit for Telco.
This is the story of how that bet paid off, not just for the hyperscalers, but for every business that now runs in the cloud. And why, twenty years later, the exact same pattern is playing out again with AI.
Before we get into what they built, it helps to understand why software alone couldn't fix this.
Data travels through fiber optic cable at roughly 200,000 kilometers per second, about two-thirds the speed of light in a vacuum. That creates hard physical minimums you simply cannot engineer around:
Those are theoretical best cases, straight-line fiber with zero processing. In the real internet of the mid-2000s, actual latency looked very different:
Now multiply that by the 50–100 microservice calls a single page load required. An Asian customer trying to use a service running in Virginia wasn't waiting 200ms. They were waiting 5,400ms. Five and a half seconds just for the network.
The math was brutal. And the only real solution was to stop trying to send data across the world and start moving the infrastructure closer to the people using it.
The hyperscalers didn't stumble into this. They executed a remarkably similar four-part playbook — one that would collectively cost somewhere between $25 billion and $60 billion in network infrastructure alone. Here's what they built.
An Internet Exchange Point (IXP) is a neutral facility where ISPs, content providers, and networks meet to exchange traffic directly without sending it through third-party transit providers. Think of them as the intersections of the internet. Places where you can switch from one network to another without paying a toll.
The major ones, Equinix with 240+ locations, DE-CIX in Frankfurt, AMS-IX in Amsterdam, HKIX in Hong Kong are where the hyperscalers planted their first flags.
The economics were compelling.
Without IXP peering:
Hyperscaler Virginia → Transit Provider → Another Transit Provider → ISP → Customer Hops: 4–6 | Latency: 40–60ms | Cost: $5–15/Mbps/month
With IXP peering:
Hyperscaler (at Equinix) → ISP (at Equinix) → Customer Hops: 1–2 | Latency: 8–15ms | Cost: Near zero (settlement-free peering)
That's a 70–80% latency reduction and a 90% cost reduction in a single architectural change. By 2015, Google, Amazon, and Microsoft each had presence in 200+ IXP locations. Facebook had 50+. Netflix deployed 10,000+ appliances across IXPs globally through their Open Connect program.
The hyperscalers had essentially built their own mesh overlay on top of the public internet one where their traffic rarely touched the paid transit network at all.
IXP peering got packets from the hyperscaler's network to the ISP's network faster. But there was still one more hop: the ISP's own network getting those packets to your front door.
The hyperscalers solved this by going inside.
Google's Global Cache program placed high-density cache servers holding 100TB to 1PB of content each, directly inside ISP facilities. Comcast, AT&T, Verizon, BT, Deutsche Telekom, NTT. Over 1,500 ISPs globally. Netflix did the same with Open Connect, eventually placing servers in over 10,000 locations inside ISP networks.
The results speak for themselves. Without ISP co-location, a Comcast customer in Philadelphia bouncing through Comcast's infrastructure to reach the hyperscaler's nearest edge faced 50–80ms minimum. With a server sitting inside the Comcast regional data center:
Customer → Comcast local node (5ms) → Hyperscaler cache inside Comcast DC (2ms) Total: 7–10ms to first byte
This is what 'last mile' optimization actually means. Not optimizing the last mile but getting inside it.
The economics worked for everyone. ISPs reduced their backbone transit costs (Netflix's Open Connect program alone saves ISPs an estimated $1 billion+ per year). Users got faster experiences. The hyperscalers got sub-10ms delivery to customers in major markets without building any new owned infrastructure.
Edge caches and IXP peering are excellent for static content. But dynamic applications, the ones making database queries, running computation, processing real-time data, can't be served from a cache. They need actual compute.
This is where the hyperscalers made the bet that created modern cloud computing.
Between 2005 and 2015, Amazon, Google, Microsoft, and Facebook built regional data centers near every major population center on the planet. Each region wasn't a single building, it was a cluster of physically separated facilities (Availability Zones) with less than 2ms latency between them, synchronized power infrastructure, and enough compute to run entire applications independently.
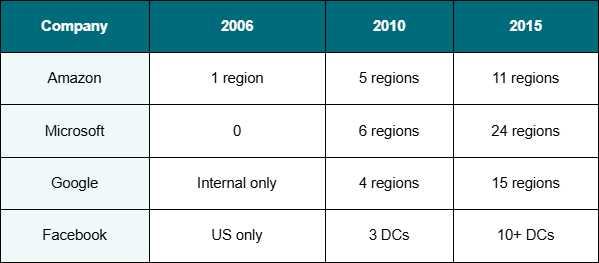
Each region represented $650 million to $2 billion in capital investment. Industry-wide for regional infrastructure alone: $60–170 billion over ten years.
The impact was immediate. An Asian customer went from experiencing 200ms+ latency routing to Virginia, to getting sub-60ms served from a regional data center in Singapore or Tokyo. A European customer went from 100–150ms to under 40ms from EU regions. The 70–95% latency reduction for international users didn't just improve user experience it unlocked entire markets that had previously been unusable.
This is the piece most people don't know exists, but it's arguably the most important of the four.
The public internet has a fundamental problem for anyone delivering consistent, high-performance services at global scale: it's unpredictable. BGP routing chooses paths based on hop count, not actual latency. Congestion during peak hours can add 50–200% to latency with no warning. There are no end-to-end SLAs. You're at the mercy of networks you don't control.
The hyperscalers decided they'd had enough. So they built their own internets.
Google's B4 Network, disclosed publicly in 2012, is a software-defined network connecting every Google facility globally. Over 1 petabit per second of capacity. It can route around failures in milliseconds, prioritize latency-sensitive traffic over bulk transfers, and engineer paths based on real-time measurements rather than static routing tables. Google also invested $2–3 billion in private submarine cable systems — FASTER, Dunant, Grace Hopper — giving them physical infrastructure that no one else could touch.
Amazon, Microsoft, and Meta followed the same path. AWS built a multi-terabit private backbone that became the foundation for Direct Connect. Microsoft built 200,000+ miles of private fiber globally, the basis for ExpressRoute. Meta's Express Backbone handles the entire data plane for their social graph, CDN, and ML training infrastructure.
The difference between public and private path for Tokyo to Virginia:
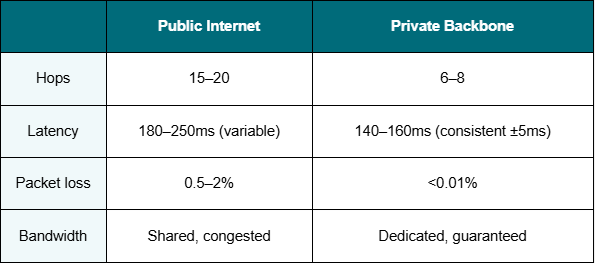
And for users in Tokyo hitting a regional Tokyo data center the entire request stays local. 10–20ms. The private backbone never even enters the picture.
By 2015, the hyperscalers had independently arrived at the same architecture, one that is now the template for every cloud provider on earth.
The request flow for a Tokyo user before this architecture: 5,000ms. After: 10ms for a cache hit. A 500x improvement.
The total network infrastructure investment (2005–2015, industry-wide, excluding data center buildings and servers): $25–60 billion.
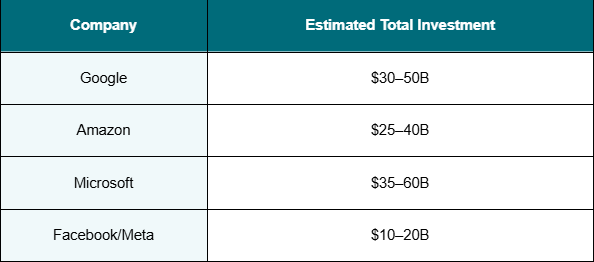
The returns were asymmetric in a way nobody fully anticipated at the time.
Every piece of infrastructure they built to solve their own latency problems became a product. Edge locations became CloudFront and Azure CDN. Private backbone access became Direct Connect, ExpressRoute, and Cloud Interconnect. Regional data centers became AWS, Azure, and GCP.
Cloud revenue trajectory:
They spent $25–60 billion on network infrastructure and accidentally created a $600 billion per year industry. That's the return on figuring out that 100 milliseconds of latency cost them 1% in sales.
Here's the uncomfortable truth twenty years later: most companies still can't afford to replicate what the hyperscalers built.
The minimum viable version of hyperscaler-class networking, 50+ edge locations, 5–10 cloud regions, a private backbone, and the operations team to run it costs $2–5 billion to build and $200–500 million per year to operate. You need to be moving 100+ terabits of traffic to justify it.
So companies are left choosing from a menu of imperfect options:
The requirements of modern applications, sub-20ms latency, private connectivity, predictable performance, global reach, consumption pricing, multi-cloud support, are real and growing. The solutions available to companies that aren't named Google or Amazon fall short. That gap is exactly what Network-as-a-Service is being built to close.
In Part 1, we watched Amazon's latency crisis force the invention of microservices and cloud computing.
In Part 2, we've watched the hyperscalers' latency problem force the invention of the modern internet's backbone.
There's a Part 3 forming right now and it's bigger than both.
AI companies face a version of the same problem the hyperscalers faced in 2005. Distributed systems. Extreme latency sensitivity. Data that can't be centralized. And infrastructure requirements that don't fully exist yet.
But there's a critical difference this time: enterprise data can't be sent to the cloud. AI inference needs to happen where the data is. AI agents need to reach across hundreds of enterprise locations simultaneously. The WAN itself needs to become as fast and reliable as a data center network.
The same three-step pattern is playing out again:
The question isn't whether that infrastructure will get built. It's who will build it and who will be the AWS of AI networking.
Part 3 is coming. The AI Networking Revolution: Why the companies at the frontier of AI need hyperscaler-class infrastructure — and why they can't just use the hyperscalers to get it.


